Войны клонов: использование канонических URL
Дата публикации: 14.09.2016
Владельцы активно развивающихся интернет-ресурсов нередко сталкиваются со следующей проблемой – одна и та же страница с одинаковым содержанием может быть найдена по нескольким различным адресам. Такое положение дел является абсолютно нормальным, но о-очень «не нравится» поисковым роботам, которые оказываются в положении буриданова осла – из множества страниц им необходимо выбрать одну, подлежащую отображению в результате. Правда, в отличие от воображаемого животного, боты не имеют обыкновения «умирать от голода» и вынуждены самостоятельно принимать решение о выборе предпочтительной страницы...или пользоваться подсказкой атрибута rel=«canonical»!
Справка
Атрибут rel=canonical, впервые введённый поисковой системой Google в феврале 2009 года, остаётся актуальным и по сей день. Этот атрибут указывает поисковым роботам на страницу, являющейся предпочтительной в ходе индексации.
Наиболее частыми причинами появления клонов/дублей страниц эксперты поисковиков Bing, Google и техподдержки Tsohost называют следующие:
- Публикация относится сразу к нескольким категориям – контент может быть найден по нескольким отдельным URL-адресам из-за различия в работе CMS,
- Динамический контент – в зависимости от особенностей пользовательского сеанса, содержание страницы изменяется,
- Некорректная конфигурация сервера – при неверной установке сертификата SSL поисковый робот не может определить, какая именно версия сайта должна быть использована: https:// или http://.
«Клоны переходят в наступление»
![Дубли]()
Дублями считаются два (или больше) документа/страницы, имеющих одинаковое содержание.
«Логика» поискового робота проста: пользователь не желает просматривать в выдаче системы одно и то же содержимое несколько раз. Значит, при обнаружении дубля требуется исключить его из индексации!
(Есть и ещё одна неафишируемая причина нелюбви поисковых систем к клонам: ни один поисковик «не хочет» заниматься монотонной постоянной обработкой миллионов дублированных интернет-страниц, расходуя на этот скучный процесс значительную часть своих мощностей)
А это значит, что даже если какая-то информация размещена на нескольких страницах, в выдаче поисковой системы отображается только одна из них! И совсем не факт, что URL, выбранный роботом, является оптимальным. Более того, он даже не обязательно на самом деле ведёт к оригинальной публикации!
Канон есть канон
Каноническая страница – первоисточник, первоначальная страница, благодаря которой результаты выдачи поисковой системы удовлетворяют целям автора контента. Каноническая ссылка, имеющая атрибут rel=canonical, указывает поисковому роботу на страницу, выбранную в качестве канонической.
Главными правилами проставления атрибута специалисты Google называют:
- Дублированные страницы должны содержать ссылки на канонический URL-адрес,
- Каноническая страница должна реально существовать и не возвращать ошибку 404,
- Каноническая страница не должна быть закрыта от индексации,
- Атрибут rel=canonical должен быть включён в код HTML,
- Атрибут rel=canonical не должен использоваться на одной странице несколько раз.
Как предотвратить дублирование контента
Запретить поисковым роботам самостоятельно «устанавливать правила» поисковой индексации достаточно просто. Для этого достаточно использовать атрибут rel=canonical в тегах каждой страницы, содержащей одинаковый контент.
Магическая формула:
При этом дополнительные свойства нужного URL-адреса канонической страницы – связанные сигналы, Page Rank и т.п. – автоматически переносятся на указанную страницу с дублированных.
Ошибки, которые могут дорого обойтись
Эксперты Google выделили несколько основных типов ошибок, которые, как показывает статистика, особенно «популярны» среди оптимизаторов и веб-мастеров, проставляющих атрибут rel=canonical:
- Первая – не всегда лучшая
Если ресурс имеет несколько страниц с нумерацией:
- пример.com/статья=заглавие=1,
- пример.com/статья=заглавие=2,
- пример.com/статья=заглавие=3,
и страницы № 2 и № 3 не являются дубликатами страницы № 1, использование атрибута rel=canonical для страницы №1 в качестве канонической – ошибка! Это ведёт к «выпадению» всех последующих страниц сайта из индекса.
![Несколько страниц навигации]()
- Абсолютное не равно относительному
Несмотря на то, что атрибут rel=canonical может использоваться как для относительных, так и для абсолютных ссылок, специалисты Google советуют отдать предпочтение именно последним – относительные ссылки в этом случае вычисляются на их основе. Если абсолютная ссылка на каноническую страницу записана без указания протокола (http:// или https://), то поисковые алгоритмы проигнорируют указание на каноничность выбранной страницы.
![Абсолютное не равно относительному]()
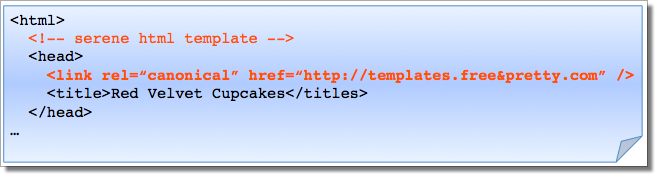
- rel=canonical используется в
Атрибут rel=canonical не должен использоваться в разделе документа кода , а должен быть включён в раздел HTML-кода – иначе он будет проигнорирован поисковыми алгоритмами.
![Использование в теге body]()
Справка
Каноническая ссылка не является строгой директивой, «обязательной к исполнению» поисковыми алгоритмами, и носит рекомендательный характер. При отсутствии атрибута поисковые роботы самостоятельно определяют каноническую страницу.
Использование атрибута rel=canonical особенно актуально для торговых интернет-площадок с большим количеством товаров: продвижение магазина с 5 000 ежедневно пополняемых основных страниц и 10 000 дублированных без указания канонических страниц может составлять серьёзную проблему и привести к штрафным санкциям со стороны поисковых систем.
Важно помнить, что использование атрибута rel=canonical:
- Не выполняется в файле robots.txt.,
- Не осуществляется с помощью инструментов удаления URL-адресов,
- Не применяется для разных адресов одной и той же страницы.